TLDR: play it here
Between Christmas and New Year this year, as every year, the Royal Institute Christmas Lectures took place. This year they were presented by Hannah Fry and the title was ‘Secrets and lies: The hidden power of maths’ (here on BBC iPlayer).
Our boy is now seven so we were keen to sit him down to watch the lectures. I remember being at school and struggling a bit with the “why” of maths. Understanding how maths is applied in the real world can really bring it to life. This year’s lectures did exactly that and he loved them!
In one of the lectures Matt Parker demonstrated a machine called MENACE created by Matt Scroggs (a copy of Donald Michie’s 1961 MENACE). MENACE is built out of matchboxes and can effectively play noughts and crosses:
Menace Machine-creator @mscroggs pitched up with his 304 matchboxes to explain how he made it. Play it for yourself online here: https://t.co/hKEOhnBqfD pic.twitter.com/fBjXAeMmP4
— Royal Institution (@Ri_Science) December 27, 2019
Matt also made this this JavaScript version of MENACE.
I found this totally fascinating and decided to make my own version, basically as a learning exercise. It had never previously occurred to me that building reinforcement-based machine learning code might be something within the reach of my capabilities.
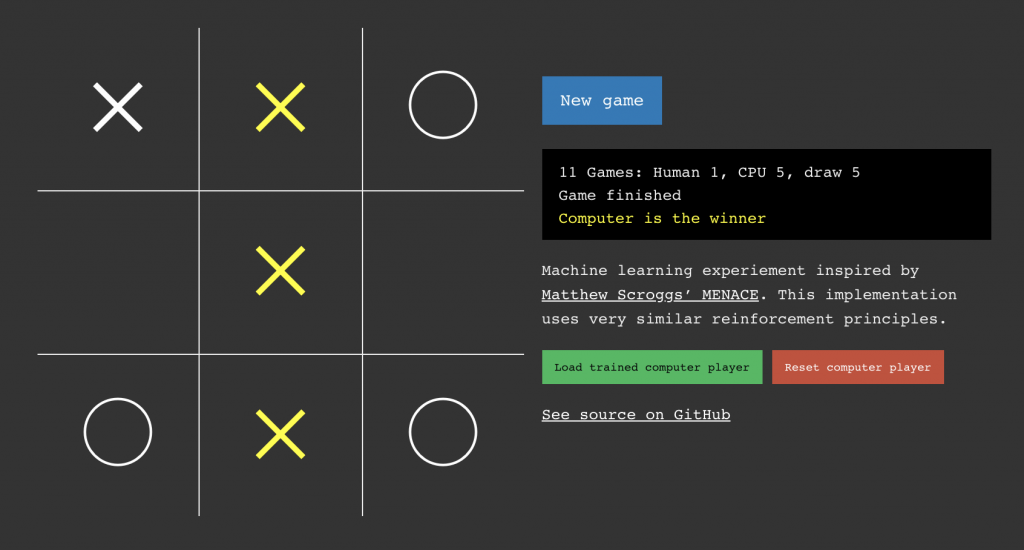
My version
Play it here – Hint: when you first load it you are playing a complete beginner. Click the green button to load a pre-trained computer player.
It is built in AngularJS which is a framework I know well, so I could quickly put together the basic game mechanic. AngularJS provides a code-light way of binding data to an interface.
The first (and easiest) part was to make a noughts and crosses game engine. This is fairly straightforward because it's such a simple game. Initially the game was just for two human players.
The second (and more interesting) part of the task was to make the computer player itself. The computer player is separate from the game program, and is notified by a window event when it is its turn to go. The game controller has a public method so the computer can ask it for the board configuration, and another method for the computer to make its turn (also used by the human player).
The computer player is in not programmed to play noughts and crosses, it has to learn how to play it from scratch. The only thing it gets told is where it can go, so it doesn't try to go in places that are already taken.
The computer player deals quite abstractly with a flat array of positions that it calls the 'stateArray'. For basic play it doesn't even need to "know" that these are arranged in a square. The process is:
- Get the state array from the game controller
- Find which places are free
- If it's the first time it's seen this configuration: Generate an object representing an equal chance of going in each free position. Otherwise: Fetch from memory the existing object representing this configuration.
- Pick a position at random from a pool of choices where the number of each choice in the pool is determined by the weightings (so for the first time it sees any given configuration there are an equal number of choices for each position).
- Make its move
- Remember where it moved and what the board configuration was at the time
- At the end of the game, for each move made, create or update a permanent record of the configuration at that time updating the weighting according to whether it won, lost or drew the game. In other words if it won it will be much more likely to make that move again. If it lost it will be less likely to make that move again (and eventually the chance will be zero) and if it drew it will be just slightly more likely to repeat the move.
Rotations
All of the above can be done without the computer player needing any sense of it being a square board. However an extra level of complexity was required for it to work like MENACE – namely rotations (technically rotations and flips). So in addition to the above I added a rotations handling service. This needs to know the board width and height. Essentially it turns that flat state array into a two dimensional array (rows and columns). These 2D boards can then be rotated or flipped. For any given board configuration the rotations service works out all the equivalent rotations that are unique on the fly. So for some configurations there would be no equivalents (e.g. a blank board, or only one item in the middle). It mirrors and flips the board so there are up to eight equivalents for any board layout (see this Google sheet).
The mirrors service itself took me about a day to grapple with, it's complicated because we need to:
- Get all rotations of the current board
- Search our history for the 'keys' of those rotations (to see if we have seen any of those rotations before)
- On finding a match get the move weighting of that match.
- 'Unrotate' the matched move weighting object (reverse the process) so it aligns to the 'real' board
- Pick a move using the unrotated weighting and make our move
- Finally re-rotate our actual move position so we can update the chance of going there again in the context of the rotated version in the history
This mirrors service itself ran to 250 lines of code. There are probably ways to do this more simply, perhaps by people more adept at maths! I got there eventually but this was by far the most complicated party of the work and took a day to write (this file and the integration with it back inside the computer player module).
I made the rotations module separate from the computer player to keep things flexible. It does not have the board dimensions hard-coded, so it could be used for other games too.
Summary
Take a look at the source code here on Github
This was great fun to build. Noughts and Crosses is of course a very trivial game with only a few hundred possible board configurations (and even fewer due to the rotations) but even so building a computer player that learns how to play it was surprisingly complicated.
I am now wondering if I can repurpose the computer player to learn how to play a simplified version of Pontoon (i.e. should it stick or twist for any given hand?). And I am also thinking about a way of building a player for Connect 4.
Connect 4 has many more places and possible configurations so it might require a different approach but I will see where I get to. The key differences are:
- In Connect 4 you can only pick a column to move in, not a row (pieces always fall to the bottom and do not float)
- In Connect 4 we can't rotate the board as it is bound in one orientation by gravity. However we could most definitely half the configurations (and must do to speed up learning) by flipping horizontally.
- The number of possibly configurations is vastly greater than in noughts and crosses so we might not be able to store every possible state, in part due to memory limitations and in part due to this being inefficient. Given that we only need to worry about rows, columns or diagonals of length 4 it might be sufficient to only consider configurations within 4x4 squares regardless of where they are on the board. This should reduce the amount of unique patterns to store. I will report back once I get going with it.
Anyway let me know what you think. Or if you have any ideas on how to simplify or improve the code let get in touch and / or make a pull request.