BBC News has added TOR mirror sites with news in both Ukrainian and Russian
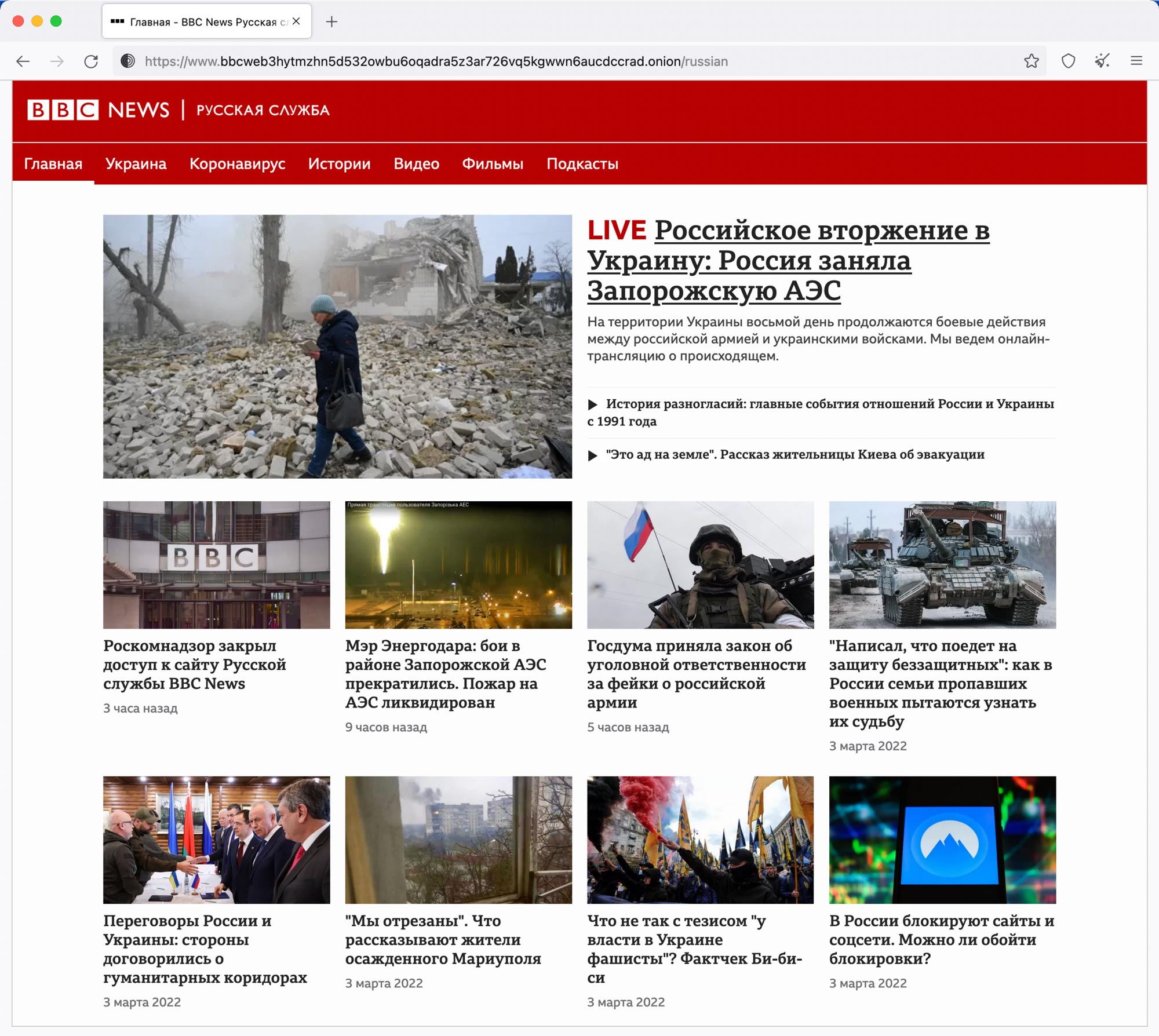
If enough of us take action we can help to get the truth to where it is desperately needed inside Russia. Flood the web with more content than they can possibly handle.

TL/DR
I wanted to write a short preamble because I think about this topic a lot, and this is more than just a confirmation bias retweet. Dan Olson’s video (below) is two hours long and covers the topic in detail.
Preamble
At the Formula 1 season finale at the Yas Marina Circuit in Abu Dhabi, emblazoned across the giant footbridge, was an ad for Crypto.com. Not having heard of it, I took a look at the website where I was greeted by Matt Damon talking to camera, and the message: “Fortune favours the brave”.
Sponsoring the Grand Prix and getting Matt Damon is expensive advertising. Crypto wants fresh blood! Those already in, and those running the exchanges are set to make a lot of money.
I don’t have a side in the crypto culture war. Except: I currently don’t have any investment in it*. Time will tell whether that’s a mistake. I’m fairly sure the only people who are vocally pro-crypto are those already invested. And this obviously undermines the usefulness of their opinions.
(*Full disclosure: I previously owned a modest amount of Bitcoin and I was lucky enough to sell it at a profit. I was curious about how it works. I made about £400 on a couple of grand investment.)
I tend to be naturally sceptical about things until I’m convinced otherwise. Despite having worked in tech for 24 years (I launched my first website for a client in 1998) I haven’t been convinced by the benefits of crypto apart from the obvious one: That evidently many people have successfully bought coins or tokens low and either sold them high, or still hold them at a higher value than when they bought them. So yes there is of course money to be made.
But because every transaction is both a buy and a sell the opposite is also true: An equal amount of money has also either been lost or is being held at a lower value than when those coins or tokens were bought. A lot of people are currently in Bitcoin negative equity (1 BTC = $35,000 today, down from $67,500 on 8 November).
Only if its value kept going up forever could everyone win.
Depending on who you listen to Bitcoin is either going to replace the US Dollar, or it will go to zero. It’s hard to get any objectivity on it, and of course you can’t predict the future. Value is a complicated subject and largely a matter of consensus or sentiment.
I’m conscious that the Twitter algorithm has me in a crypto-skeptic bubble but many of the arguments presented in it are well reasoned. In an attempt to balance things out I follow and have read or listened to a number of crypto advocates: Changpeng, Vitalik, Michael Saylor, Jack Dorsey, Chris Dixon and Anthony Pompliano as well as a couple of NFT guys (although I had to mute one, he was too tedious). Bored apes are everywhere and now we have hexagonal profile pictures too. I enjoyed Lex Fridman’s interview with Pomp. But obviously he is inherently very biased.
Oh and – guys – the whole laser eyes thing is not exactly helping it not feel like a cult.
The technology is certainly interesting but I’m not convinced that it is necessary or beneficial to society. Yes, even taking into account the fiat inflation problem. If you’re a card-carrying libertarian you probably don’t give a shit about societal benefits so long as something can make you personally richer. In which case by all means do your thing.
Friends who are crypto investors will likely roll their eyes at this post (not another hater!) But I believe privately they’re thinking “shut up dude” because I’m talking down their investment. I understand that – I have investments in tech stocks and I tend not to enjoy negative posts about those either.
Anyway I did previously attempt a blog post about all of it but there are too many aspects that each start to unfurl into complicated arguments that require well researched evidence and for which there will be counterexamples and frankly despite being in tech I’m not an expert on any of it so I decided there is no point, other than that I like to occasionally blog to iron out unresolved things that have been going around in my head.
Then this morning I saw this video created by @FoldableHuman and it really is very in-depth and starts from the beginning in 2008. I felt it was well worth sharing in more than just a tweet, hence this post.
Enjoy – or be pissed off by it – as per your conditioning!
Footnote
I can’t predict the future and am open to the possibility that I might turn out to be wrong about everything!

Remember Net magazine? It ended publication a few months ago after 25 years on the news stand. As a keen amateur / pre-junior designer I used to buy it to be inspired and learn various coding top tips.
I blogged about this back in 2013 but this morning while I was searching through old files to create the Pirata work page on this site I found the actual PDF of the article they published about us. Rather than let it languish on my backup drive it deserves to be on the web.
I’m not loving my profile photo (no fault of the Photographer, James) – I was much heavier back then and resemble a kind of young Steve Ballmer, but anyway here is the article:
Read more about Pirata here.

Better late than never! I have been lucky enough to not really need a portfolio for years. But it seemed a shame not to have one and, after all, I do know how to make websites so here we are. I am slowly adding both new and old projects to this site over the coming weeks.
This one is something I’ll always be proud of – at Pirata (RIP) we built a new and innovative site for McLaren, starting work on it in late 2009 and launching the first version – the award-winning ‘The Race 1.0b’ – for the start of the 2010 Formula1 season. We continued to reinvent, maintain and support the site for several years.
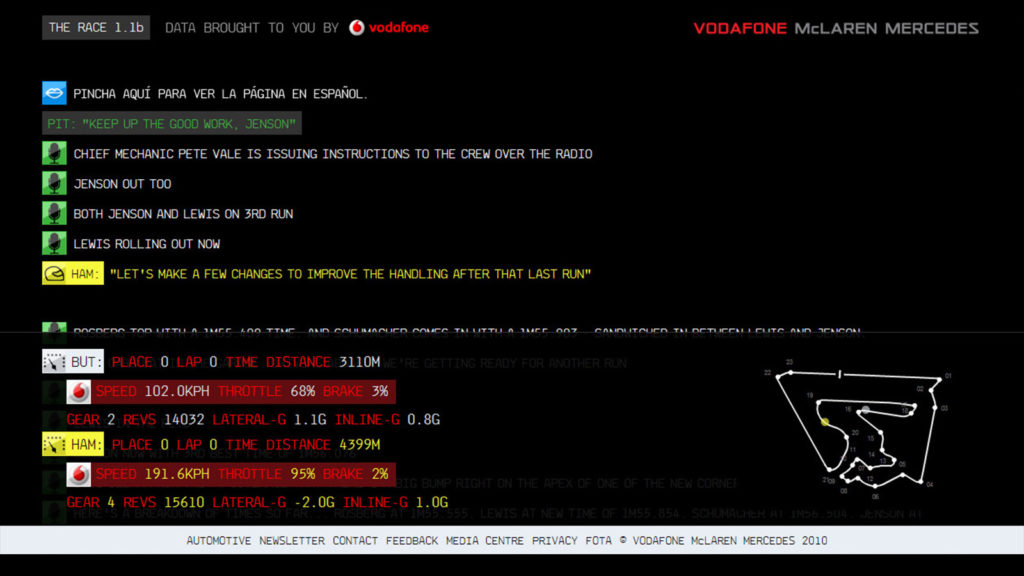
More than just a typical site, it was built around race weekends when it became a live dashboard with realtime data from the cars, drivers and team wherever they were in the world.
It goes without saying that it was a huge team effort, we had some some incredibly talented designers, developers and producers.
Take a look at my McLaren portfolio page for more details and screenshots.
I have plenty more more work to add both recent and from my archive. You can find all projects on the Work page.
On being a creative person trapped inside a technical person’s brain
TLDR: play it here
Between Christmas and New Year this year, as every year, the Royal Institute Christmas Lectures took place. This year they were presented by Hannah Fry and the title was ‘Secrets and lies: The hidden power of maths’ (here on BBC iPlayer).
Our boy is now seven so we were keen to sit him down to watch the lectures. I remember being at school and struggling a bit with the “why” of maths. Understanding how maths is applied in the real world can really bring it to life. This year’s lectures did exactly that and he loved them!
In one of the lectures Matt Parker demonstrated a machine called MENACE created by Matt Scroggs (a copy of Donald Michie’s 1961 MENACE). MENACE is built out of matchboxes and can effectively play noughts and crosses:
Menace Machine-creator @mscroggs pitched up with his 304 matchboxes to explain how he made it. Play it for yourself online here: https://t.co/hKEOhnBqfD pic.twitter.com/fBjXAeMmP4
— Royal Institution (@Ri_Science) December 27, 2019
Matt also made this this JavaScript version of MENACE.
I found this totally fascinating and decided to make my own version, basically as a learning exercise. It had never previously occurred to me that building reinforcement-based machine learning code might be something within the reach of my capabilities.
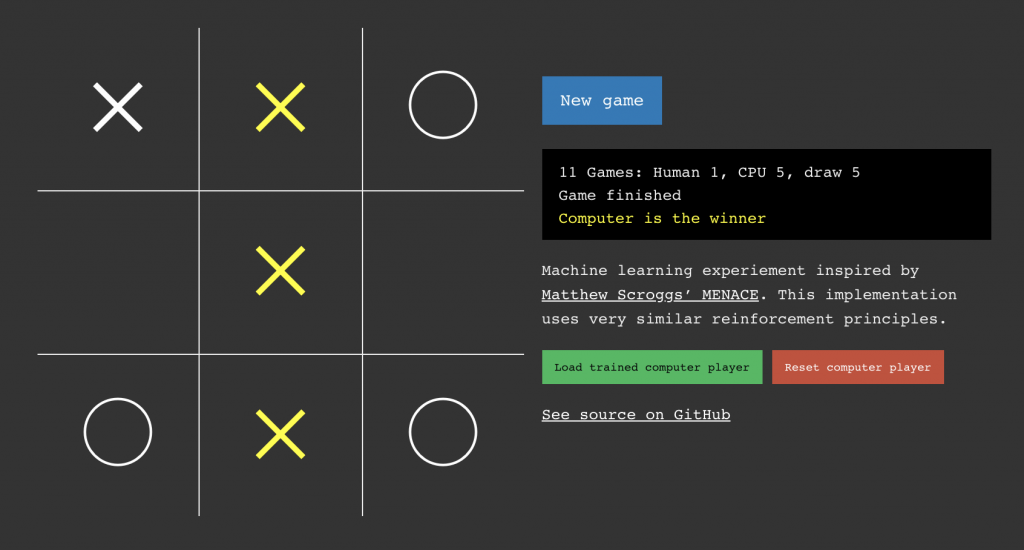
My version
Play it here – Hint: when you first load it you are playing a complete beginner. Click the green button to load a pre-trained computer player.
It is built in AngularJS which is a framework I know well, so I could quickly put together the basic game mechanic. AngularJS provides a code-light way of binding data to an interface.
The first (and easiest) part was to make a noughts and crosses game engine. This is fairly straightforward because it's such a simple game. Initially the game was just for two human players.
The second (and more interesting) part of the task was to make the computer player itself. The computer player is separate from the game program, and is notified by a window event when it is its turn to go. The game controller has a public method so the computer can ask it for the board configuration, and another method for the computer to make its turn (also used by the human player).
The computer player is in not programmed to play noughts and crosses, it has to learn how to play it from scratch. The only thing it gets told is where it can go, so it doesn't try to go in places that are already taken.
The computer player deals quite abstractly with a flat array of positions that it calls the 'stateArray'. For basic play it doesn't even need to "know" that these are arranged in a square. The process is:
- Get the state array from the game controller
- Find which places are free
- If it's the first time it's seen this configuration: Generate an object representing an equal chance of going in each free position. Otherwise: Fetch from memory the existing object representing this configuration.
- Pick a position at random from a pool of choices where the number of each choice in the pool is determined by the weightings (so for the first time it sees any given configuration there are an equal number of choices for each position).
- Make its move
- Remember where it moved and what the board configuration was at the time
- At the end of the game, for each move made, create or update a permanent record of the configuration at that time updating the weighting according to whether it won, lost or drew the game. In other words if it won it will be much more likely to make that move again. If it lost it will be less likely to make that move again (and eventually the chance will be zero) and if it drew it will be just slightly more likely to repeat the move.
Rotations
All of the above can be done without the computer player needing any sense of it being a square board. However an extra level of complexity was required for it to work like MENACE – namely rotations (technically rotations and flips). So in addition to the above I added a rotations handling service. This needs to know the board width and height. Essentially it turns that flat state array into a two dimensional array (rows and columns). These 2D boards can then be rotated or flipped. For any given board configuration the rotations service works out all the equivalent rotations that are unique on the fly. So for some configurations there would be no equivalents (e.g. a blank board, or only one item in the middle). It mirrors and flips the board so there are up to eight equivalents for any board layout (see this Google sheet).
The mirrors service itself took me about a day to grapple with, it's complicated because we need to:
- Get all rotations of the current board
- Search our history for the 'keys' of those rotations (to see if we have seen any of those rotations before)
- On finding a match get the move weighting of that match.
- 'Unrotate' the matched move weighting object (reverse the process) so it aligns to the 'real' board
- Pick a move using the unrotated weighting and make our move
- Finally re-rotate our actual move position so we can update the chance of going there again in the context of the rotated version in the history
This mirrors service itself ran to 250 lines of code. There are probably ways to do this more simply, perhaps by people more adept at maths! I got there eventually but this was by far the most complicated party of the work and took a day to write (this file and the integration with it back inside the computer player module).
I made the rotations module separate from the computer player to keep things flexible. It does not have the board dimensions hard-coded, so it could be used for other games too.
Summary
Take a look at the source code here on Github
This was great fun to build. Noughts and Crosses is of course a very trivial game with only a few hundred possible board configurations (and even fewer due to the rotations) but even so building a computer player that learns how to play it was surprisingly complicated.
I am now wondering if I can repurpose the computer player to learn how to play a simplified version of Pontoon (i.e. should it stick or twist for any given hand?). And I am also thinking about a way of building a player for Connect 4.
Connect 4 has many more places and possible configurations so it might require a different approach but I will see where I get to. The key differences are:
- In Connect 4 you can only pick a column to move in, not a row (pieces always fall to the bottom and do not float)
- In Connect 4 we can't rotate the board as it is bound in one orientation by gravity. However we could most definitely half the configurations (and must do to speed up learning) by flipping horizontally.
- The number of possibly configurations is vastly greater than in noughts and crosses so we might not be able to store every possible state, in part due to memory limitations and in part due to this being inefficient. Given that we only need to worry about rows, columns or diagonals of length 4 it might be sufficient to only consider configurations within 4x4 squares regardless of where they are on the board. This should reduce the amount of unique patterns to store. I will report back once I get going with it.
Anyway let me know what you think. Or if you have any ideas on how to simplify or improve the code let get in touch and / or make a pull request.
![]()
cappchur is a simple data capture app for tablet and mobile, aimed primarily at the exhibition, trade show and retail markets. The project is a collaboration with Paul Pike.
The app launched this week and is available for iPad, iPhone or iPod Touch for FREE in the App Store, and for Android tablets and phones here on Google Play.
cappchur has been designed to be simple and intuitive without any complicated set up process. Once you've installed the app you can start using it straight away, with no need to register up-front. You can also use it completely offline.
If you or someone you know is running a stall or exhibiting at an event please give our app a try and let us know what you think: cappchur.com.
If you missed deepdream in the news then go and read this article and the original research blog post, and / or look at the original gallery full screen.
Good. Now, given that Google made the software open source, there's lots more to look at. Check out the #deepdream hashtag on Twitter.
And this Twitch channel let's you "live shout objects to dream about".
And finally, these two videos are worth a watch:
Journey through the layers of the mind from Memo Akten on Vimeo.
Noisedive from Johan Nordberg on Vimeo
[Edit]
Also, someone ran it on a clip from Fear and Loathing...

Google’s new Photos app seems pretty great, with a consistent experience between the web and its native Android and iOS versions. The way your photos are organised is better than in Apple’s app, but the clincher is that they give you unlimited online storage if you're willing to have them compress the originals. Given that (for me) this is just for family snaps, that is fine.
My iCloud storage has been full for weeks, and a combination of not being bothered enough to get round to it and not being sure I want to pay for the service (5GB feels tight, given I recently spent £ hundreds on a new iPhone) has led me to leave it like that. So goodbye iCloud Photo Library.
And as a it happens you can still post photos to iCloud shared libraries (which are, confusingly, separate from the iCloud Photo Library) direct from the Google Photos app.
Anyway two days into using it a couple of things are eluding me:
- A lot of people are tweeting about how impressive the facial recognition is, and the feature was demonstrated in the Google IO Keynote, but my Google Photos app (and also on the web) has no mention of faces anywhere and no apparent means of manually tagging faces - despite my library being full of photos of my family. Perhaps they're rolling it out incrementally.
- Google has rather cleverly tagged and grouped a load of objects and things such as cats, cars, trains and food. However these collections contain some notable mistakes. A photo of one of my cats sleeping has appeared in the 'food' set, for example. Oddly there seems to be no way of untagging these things. Surely if you could then this could theoretically help its learning algorithm.
I'm guessing these things will be sorted out in due course, but there's a chance I'm just missing something obvious. I've searched Google and Twitter but can't find anyone else with the same problem (I mostly care about the face recognition).
Anyone else?
Contact
© 2023 Ade Rowbotham Ltd